RESEARCH
Conference and Journal Publications

PROJECTS
Project Experiences
Lost and Found
A web and Android app for a lost-and-found platform, enabling users to report and search items via text and image inputs with intuitive UI/UX.
EPI-Graph
EPI-graph helps to localize the epileptogenic network from interictal activity (using SEEG) recorded from brain structures of epilepsy patients for surgical aid.
Medical-LLM
Developed an AI tool which utilized Natural Language Processing to suggest personalized mental health guidance backed by the research on National Library of Medicine and provides it to the user in a simplified manner.
Multiple Representation Number Learning
Trained an attention-based LSTM model to translate between Arabic numerals, number words, and visual blocks under three conditions: (1) numerals + words, (2) blocks + words, and (3) all three combined. Training data was carefully curated to optimize learning across formats and support compositional generalization.
Color Music Analysis
Built a Python and R pipeline to process gaze and behavioral data from a color-coded music learning experiment. Extracted trial-wise fixation metrics and analyzed learning effects using linear mixed models, revealing how visual cues influence musical skill acquisition.
Speech and Behavior Alignment Editor
Built a Streamlit app that transcribes speech from video using IBM Watson and aligns it with behavioral trial data using timestamp metadata. The tool enables speaker-attributed editing, millisecond-precision correction, and exportable, trial-annotated transcripts—automating hours of manual research work.
PROJECT
Lost and Found
A multi platform lost-and-found system for campuses
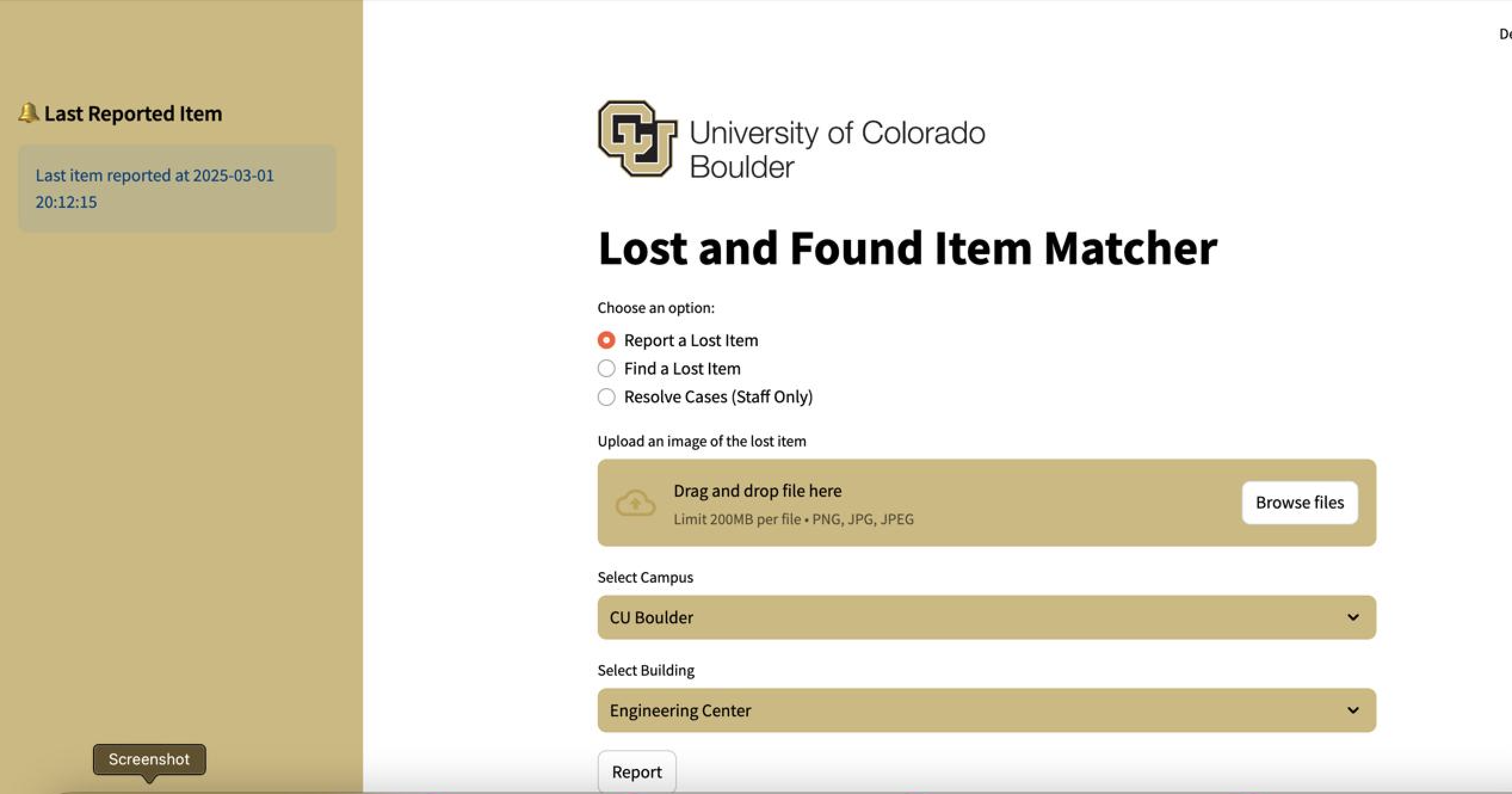
Description: A Web app and an Android app for a lost-and-found platform. The platform enables users to report and search items using text description and/or images, while staff can authenticate to resolve cases and manage item retrieval. It integrates a MySQL database for structured data storage and uses Google Cloud Storage to securely store uploaded images.
GitHub: https://github.com/trishthakur/lost-found
Technologies Used: Python, Streamlit, GCS, MySQL
Key Features:
- Report a Lost Item: Users can upload an image or take a picture of their lost item and provide information about the campus and building where the item was lost.
- Find a Lost Item: Users can search for lost items either by text description or by uploading an image.
- Resolve Cases (Staff Only): Staff can mark lost items as resolved and provide owner details for retrieval.
- User Authentication: Admin users can access and resolve lost items through a login system.
- Database Management: The application manages a MySQL database for storing lost items, resolved items, users, and locations.
- Image data storage: The images that the person reporting uploads is stored in a google cloud storage bucket.
Outcome: Successfully delivered a cross-platform lost-and-found solution through a web and Android app. It enhances efficiency and reliability for both users and campus staff.
PROJECT
EPI-Graph
A research-driven epileptogenic localization tool
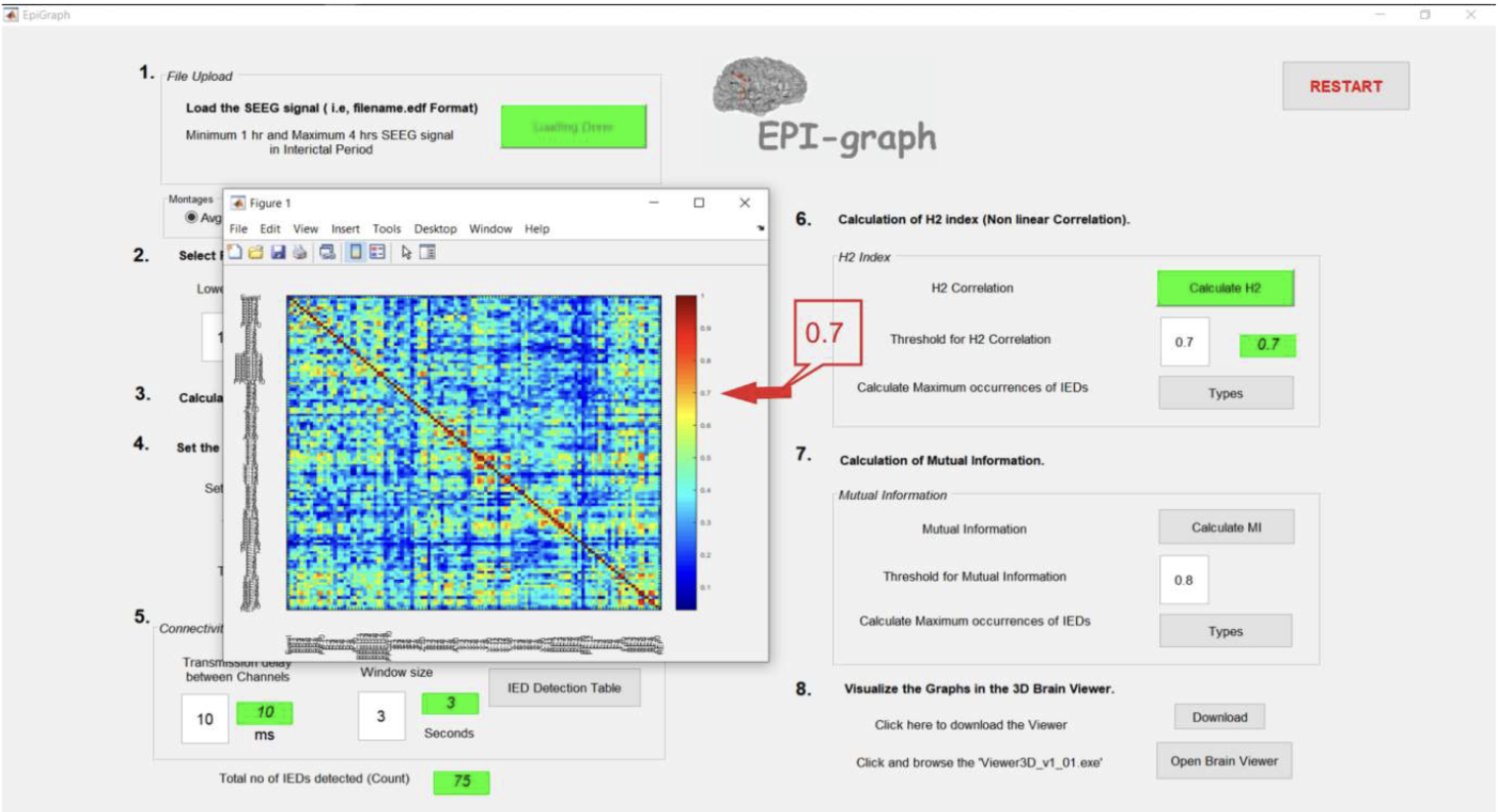
Description: EPI-Graph is a neuroinformatics tool that assists in localizing epileptogenic networks from stereo-EEG (SEEG) recordings. It leverages nonlinear correlation, mutual information, and graph theory to provide clinical insights into epileptic activity, especially for pre-surgical evaluation.
GitHub: https://github.com/sasibonu/EPI-graph
Publication: https://pubmed.ncbi.nlm.nih.gov/36345880/
Technologies Used: Python, NumPy, SciPy, MATLAB, Jupyter
Key Features:
- Nonlinear H2 energy correlation matrices for brain signal similarity.
- Graph-theoretic computation of node strengths and thresholds.
- Visualization of SEEG channels with epileptogenic potential.
Outcome: Successfully used to analyze patient SEEG data and published in neuroscience journals.
PROJECT
Medical LLM
AI-Powered Mental Health Assistant
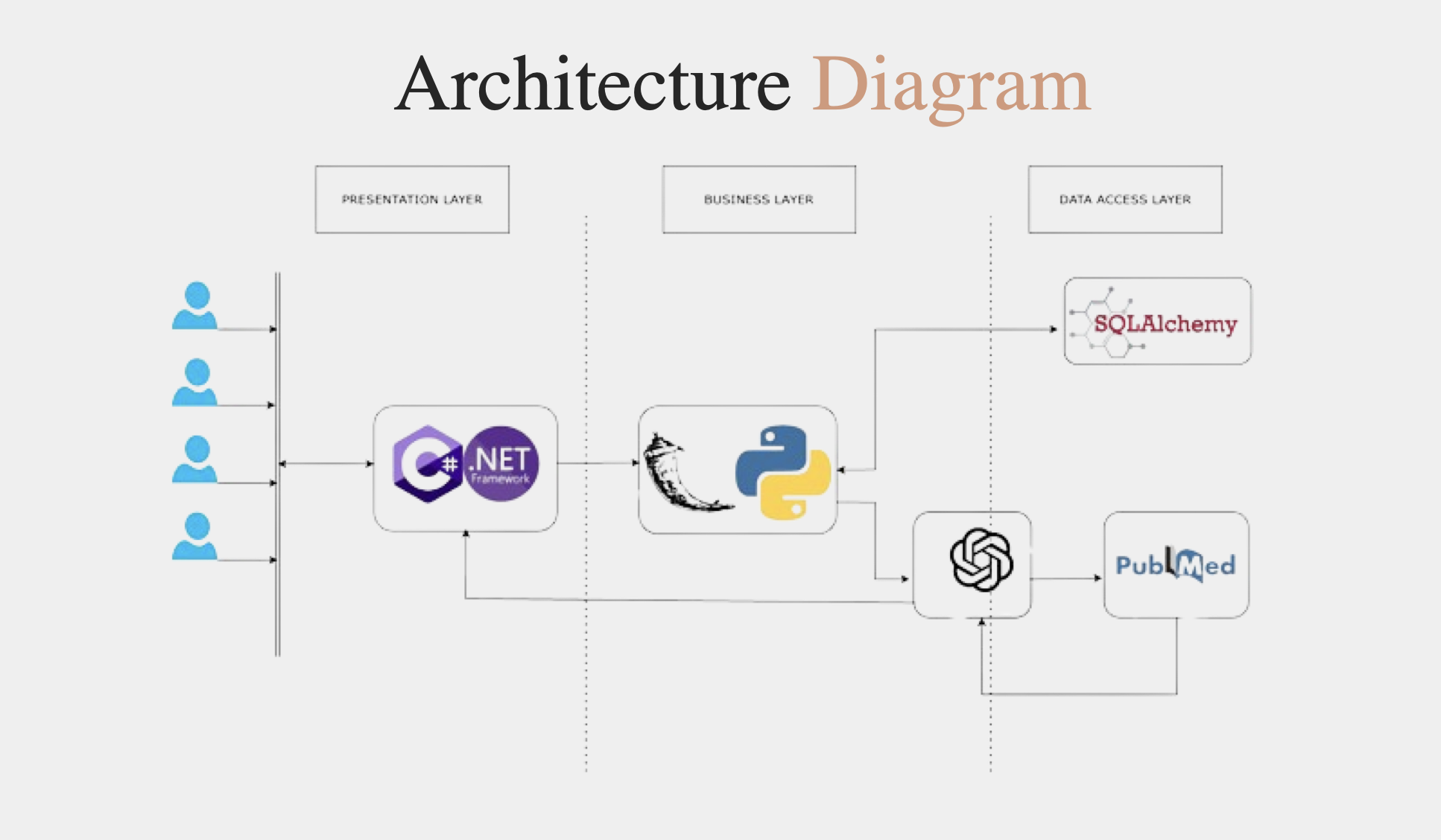
Description: Developed an AI mental health assistant powered by GPT and PubMed integration to provide evidence-based support for users seeking help. Designed using a hybrid .NET and Flask stack, the system is modular, scalable, and deployable across environments.
GitHub: https://github.com/sasibonu/Medical-LLM
Technologies Used: Python, Flask, .NET, SQLAlchemy, GPT APIs, PubMed API, HTML/CSS, JavaScript
Key Features:
- Integrated GPT with PubMed for clinical-grade, real-time mental health insights.
- Modular API orchestration with clean architecture and SQL-backed data flow.
- Automated summarization of user health queries using NLP techniques.
Outcome: Delivered a working demo, improving accessibility to mental health resources through AI-driven responses.
PROJECT
Multiple Representation Number Learning
Attention-Based Multi-Modal Number Translation
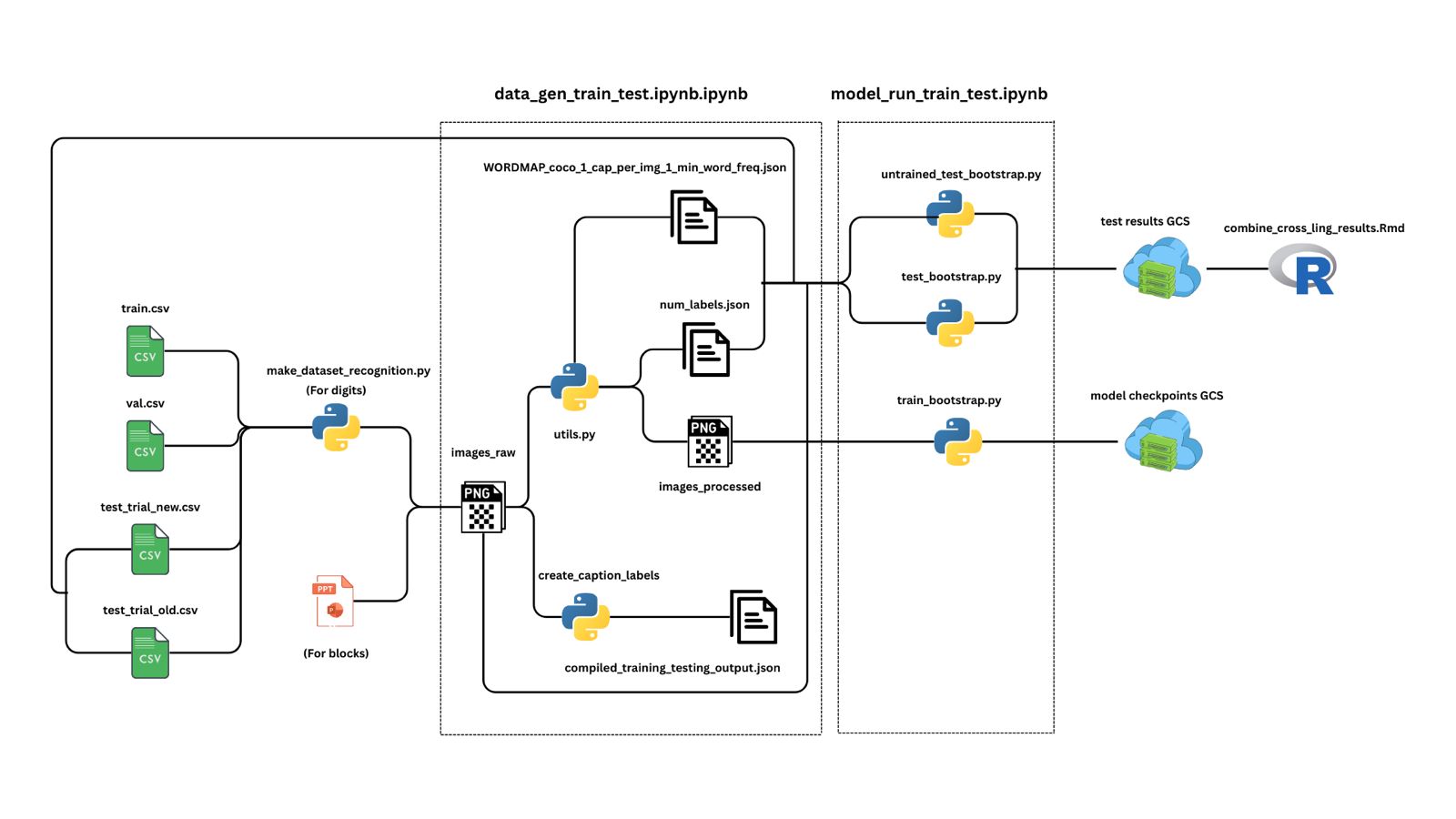
Description: Developed an attention-based LSTM model that translates between Arabic numerals, number words, and visual block representations. Evaluated the model under three input combinations to simulate cognitive learning processes and assess numerical understanding across modalities.
Technologies Used: Python, PyTorch, NumPy, Matplotlib, Pandas
Key Features:
- Attention-driven LSTM architecture for sequence-to-sequence number translation.
- Three experimental conditions: numerals+words, blocks+words, and all combined.
- Custom accuracy measure using attention-weighted probability comparisons.
Outcome: Achieved 75% accuracy on novel test sets using Arabic numerals and 65% accuracy with visual block representations, demonstrating effective cross-modal learning.
PROJECT
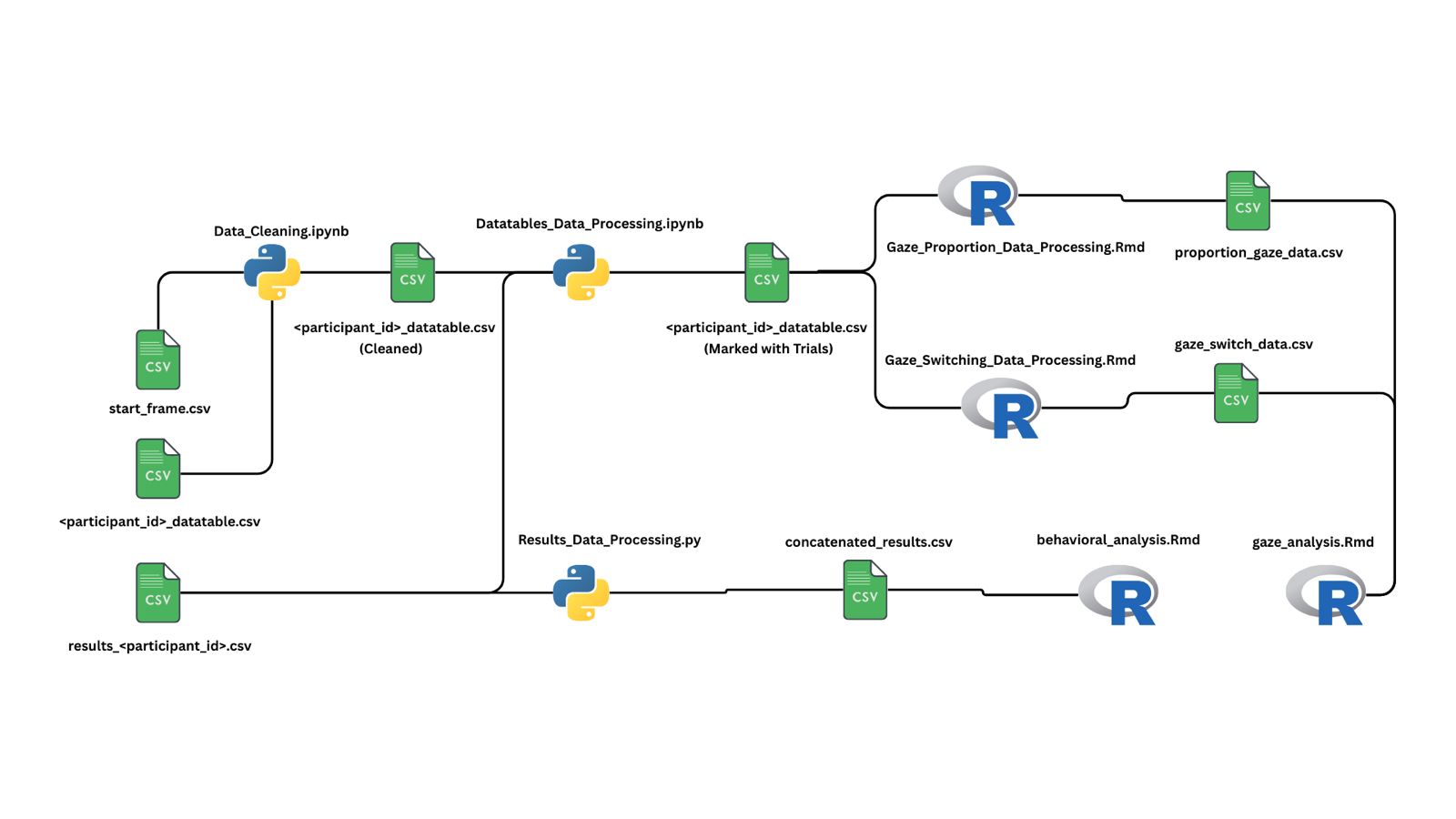
Color Music Analysis
A gaze and behavior analysis pipeline for musical learning
Description: This project investigates how visual cues influence musical learning by analyzing gaze and behavioral data from an experiment involving four conditions: the presence or absence of keyboard stickers and colored musical notation. The data pipeline supports cleaning, processing, and statistical analysis to assess how these visual aids impact participants' learning and attention.
Technologies Used: Python, R, pandas, PySpark, tidyverse, ggplot2
Key Features:
- Automated data flow from raw gaze and behavioral logs to clean, trial-segmented datasets.
- Computation of gaze proportions, gaze switches, and trial-level behavioral metrics.
- Statistical models assessing the effect of visual conditions on learning performance.
Outcome: The analysis revealed that colored notation significantly accelerated learning compared to other conditions, demonstrating the strong impact of color-based visual encoding in music education.
PROJECT
Speech and Behavior Alignment Editor
Streamlined Speech Transcription & Trial Synchronization
Description: Developed a Streamlit-based editor that uses IBM Watson’s Speech-to-Text API to transcribe speech from research videos and synchronize it with behavioral trial metadata. The tool automates the alignment process between spoken dialogue and experimental trials, providing researchers with a precise, editable view of time-coded transcripts.
Technologies Used: Python, Streamlit, IBM Watson API, pandas
Key Features:
- Speech-to-text transcription with speaker attribution and millisecond-level timestamps.
- Automated mapping of speech with behavioral trial data using timestamp metadata.
- Interactive dashboard for editing dialogue, correcting errors, and exporting clean transcript tables.
Outcome: Replaced hours of manual annotation with a single streamlined interface, enabling accurate word-by-word transcript alignment with experimental trials, significantly boosting research efficiency.